Large Language Model (LLM) Chatbot

- Published on
- Duration
- 1 Month
- Role
- Developer
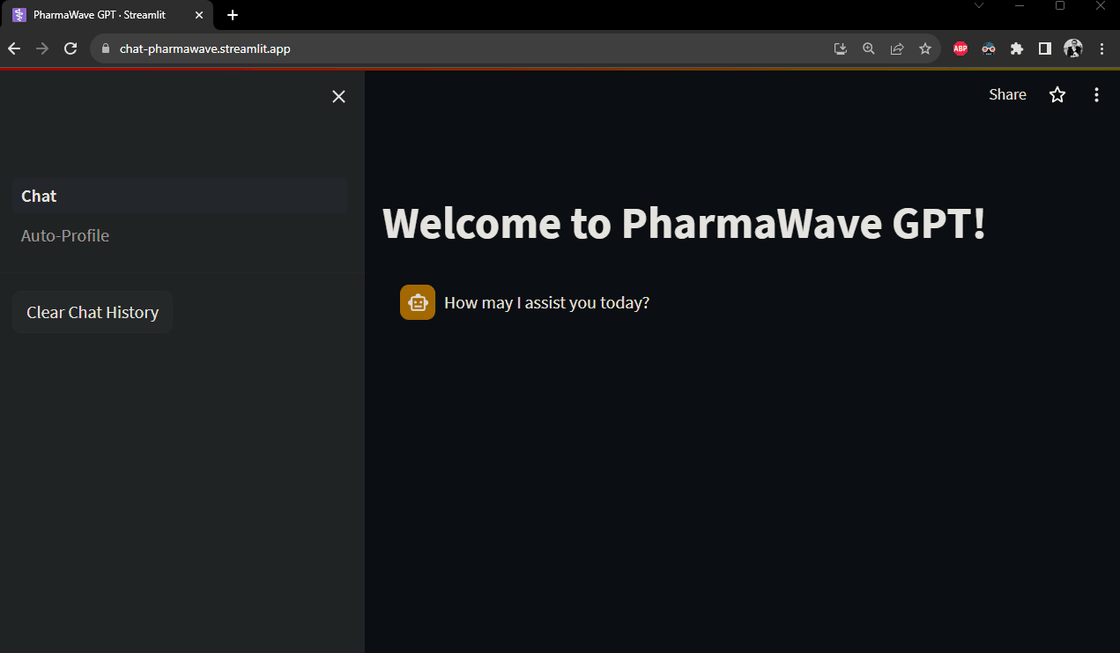

PharmaWave GPT (fictional company) is a web application that allows users to chat with a Large Language Model (LLM) chatbot and was built using Meta AI's Llama-2 LLM and deployed using Streamlit and Python.
The goal was to simulate an in-house chatbot that could be used to answer questions about the company and its products, and also to allow data analyst/scientists to upload the company's private data to do EDA, saving the hassle of having to recode the same EDA steps over and over again.
Link to the web application: PharmaWave GPT
The challenge
Other than the usual challenges of building a web application, the main challenge was to deploy the LLM model in a way that it could be used by the imaginary "staff".
Training a model from scratch would be too time-consuming and costly, so the team decided to use an open-sourced model, and train from there. However, storage was also an issue as most of the open-sourced models were too large to be deployed on Streamlit or GitHub. For context, the Llama-2 model was about 800GB in size.
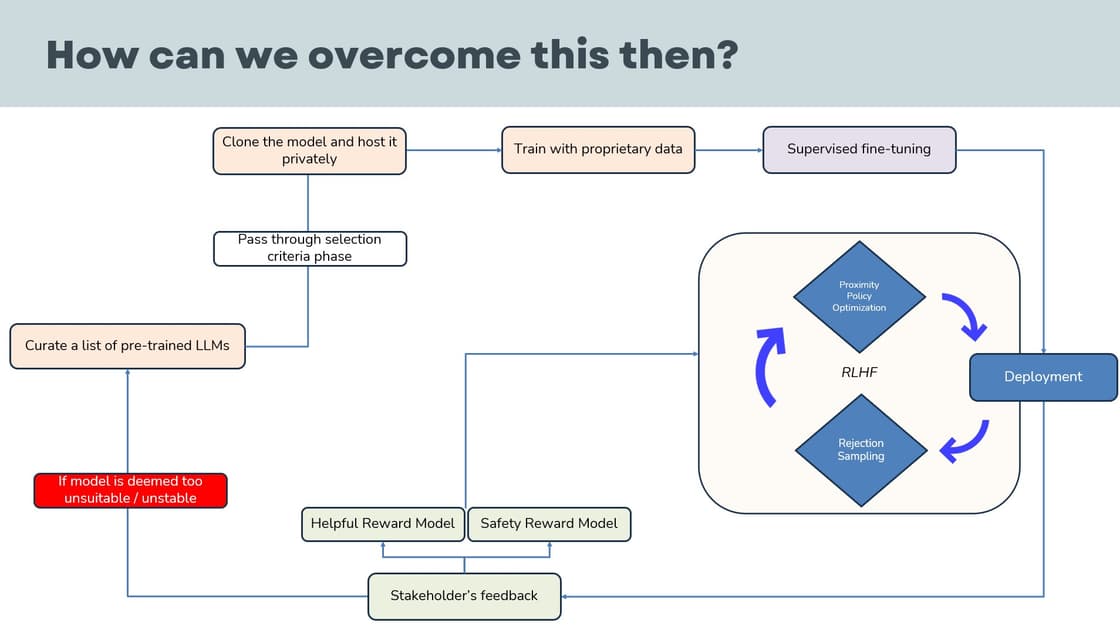
Proposed Solution
Thus the team turned to Replicate, a platform that allows users to deploy their models in a few clicks. Using an API key approach, the team was able to deploy the model on Replicate, keeping the code clean and storage costs low.

As the organization is billed per query, the team will suggest to give role-based access to the chatbot, so that each department is billed accordingly.
Model Deployment
To prepare the model for deployment, the team used the following steps:
Training LLMs can be very resource intensive. It is recommended to requisite a cloud VM instance with GPU capabilities, such as LambdaLabs or PaperSpace.
- Clone the model from Github
- Requisite a GPU Cloud Instance on PaperSpace

- Install Cog & Docker
sudo curl -o /usr/local/bin/cog -L https://github.com/replicate/cog/releases/latest/download/cog_`uname -s`_`uname -m`
sudo chmod +x /usr/local/bin/cog
cd path/to/your/model
cog init
Cog is a command-line tool for deploying machine learning models to Replicate. It is designed to be used with any machine learning framework, including PyTorch, TensorFlow, and scikit-learn.
Docker is a set of platform as a service (PaaS) products that use OS-level virtualization to deliver software in packages called containers. Containers are isolated from one another and bundle their own software, libraries and configuration files; they can communicate with each other through well-defined channels.
- Using the ./download.sh script, we will download the model weights.
- Build a docker image & Tensorize the weights
cog run /script/download-weights
- Once the docker image is built, the model is pushed to Replicate.

- Next, test a prediction locally.

- Assess if the prompts are working as intended, if not a training dataset will be required to fine-tune the model.
Model Fine-tuning
Using this dataset as a simulation that this is "sensitive information".
We will train the model using Replicate's API and library:
import replicate
training = replicate.trainings.create(
version="base-model",
input={
"train_data": "training-data",
},
destination="the repo"
)

- Phew! The model is now trained and ready to be deployed.
Video Demo
Click on the image below to watch the video demo of the web application.
Closing Thoughts
This was the first time I am working with a LLM model, and it was a great experience. I was able to learn more about the model and how it can be used in a real-world setting. I also learnt how to deploy a model on Replicate, and how to use Streamlit to build a web application.